Abstract
The semantic segmentation of parts of objects in the wild is a challenging task in which multiple instances of objects and multiple parts within those objects must be detected in the scene. This problem remains nowadays very marginally explored, despite its fundamental importance towards detailed object understanding. In this work, we propose a novel framework combining higher object-level context conditioning and part-level spatial relationships to address the task. To tackle object-level ambiguity, a class-conditioning module is introduced to retain class-level semantics when learning parts-level semantics. In this way, mid-level features carry also this information prior to the decoding stage. To tackle part-level ambiguity and localization we propose a novel adjacency graph-based module that aims at matching the relative spatial relationships between ground truth and predicted parts. The experimental evaluation on the Pascal-Part dataset shows that we achieve state-of-the-art results on this task.
The full paper can be downloaded from here
Code and Dataset
The code for the training and the evaluation of the proposed method is available on GitHub here.
The datasets and some checkpoints and predictions of interest are available.
Method
The overall architecture of the proposed approach is illustrated below.
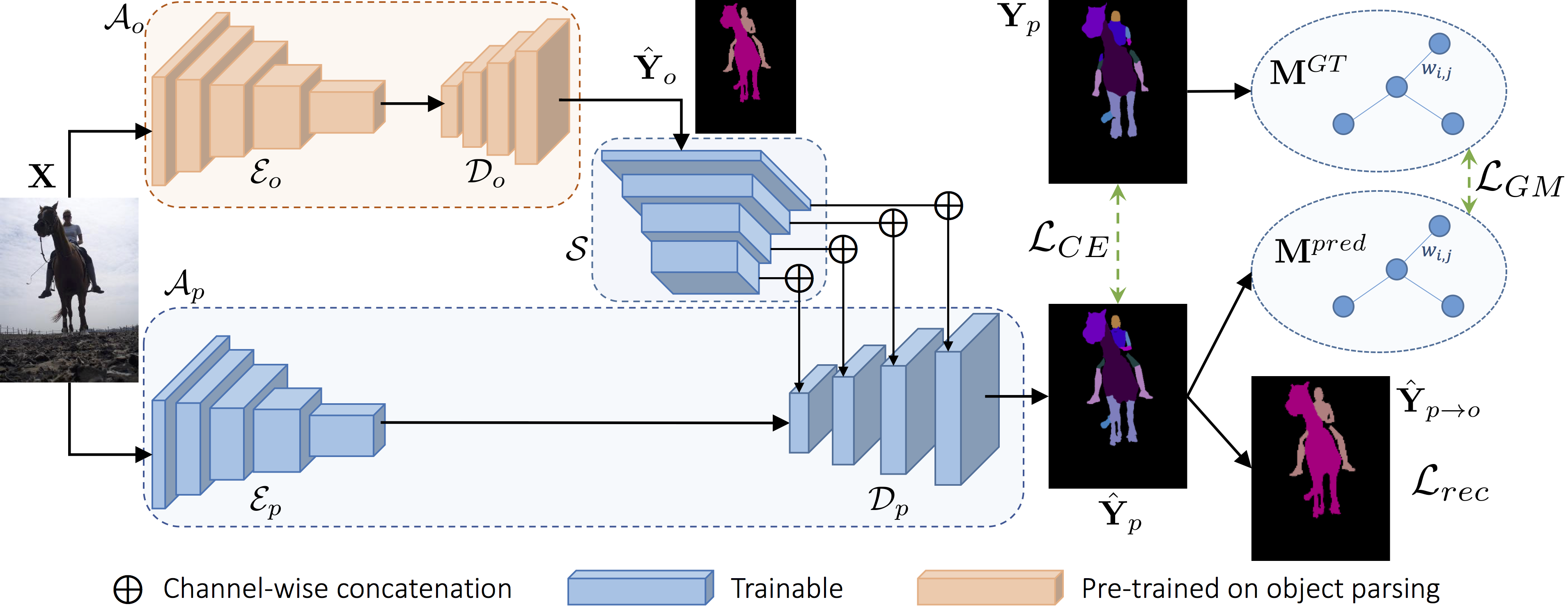
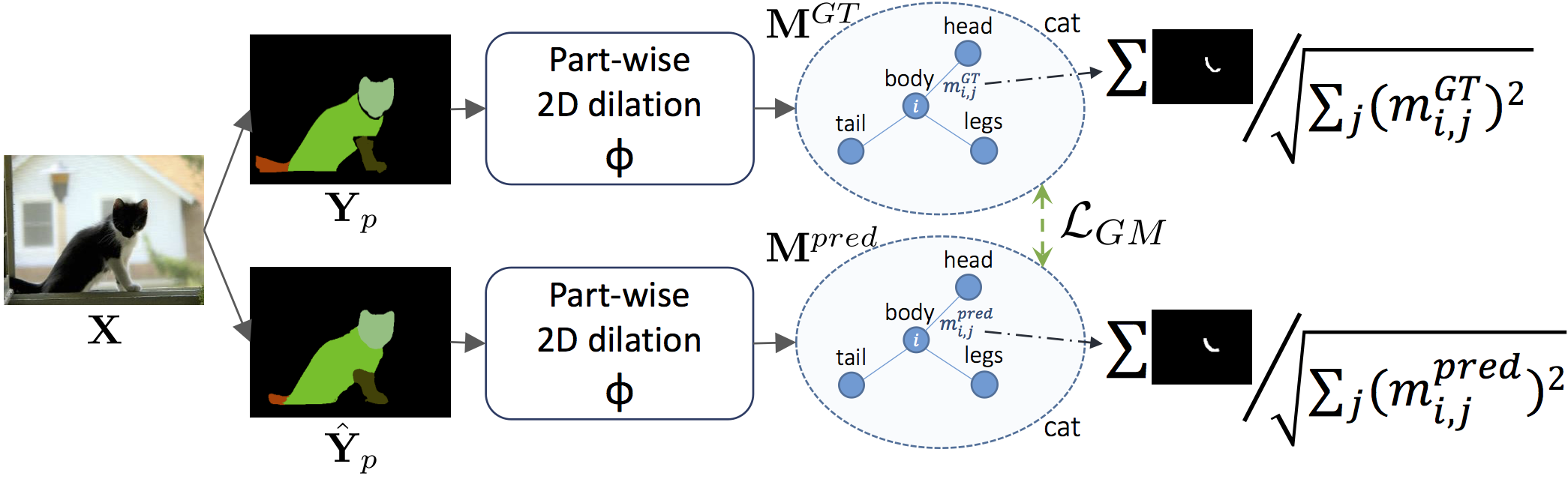
The graph matching module is shown more in detail below.
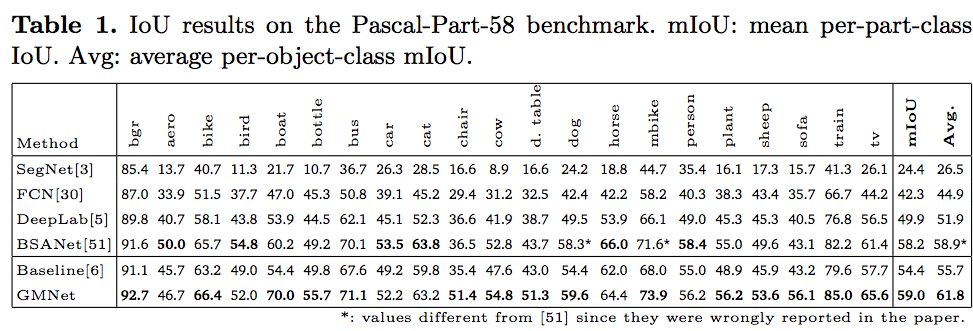
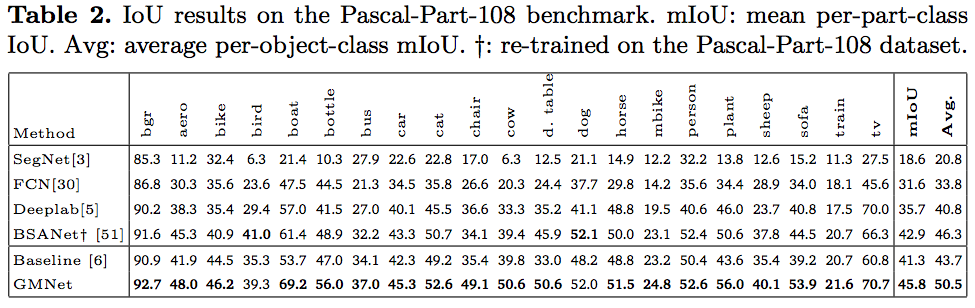
Results
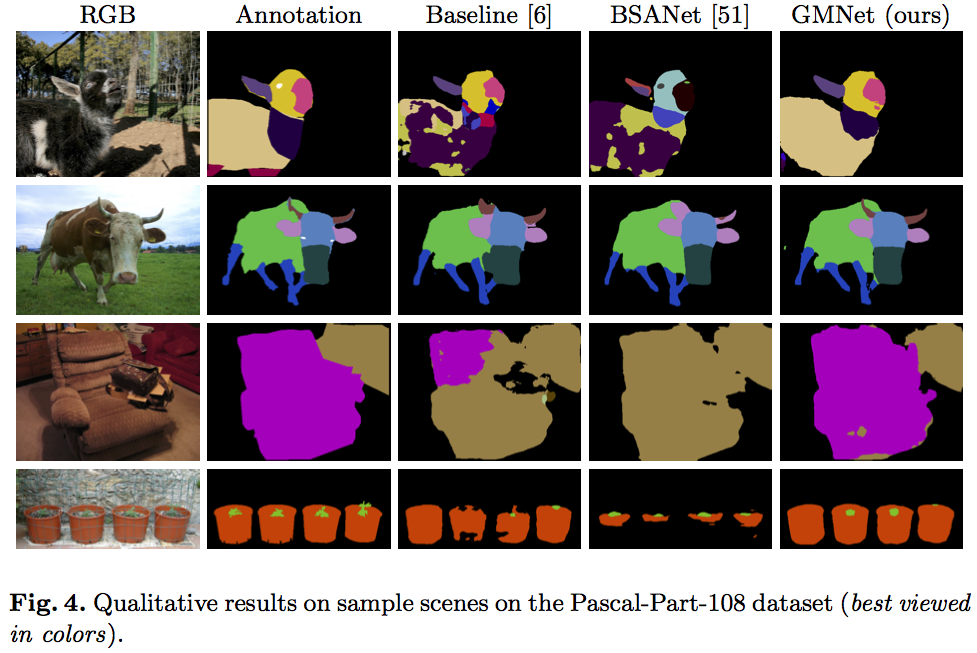
The main quantitative and qualitative results are reported in the following.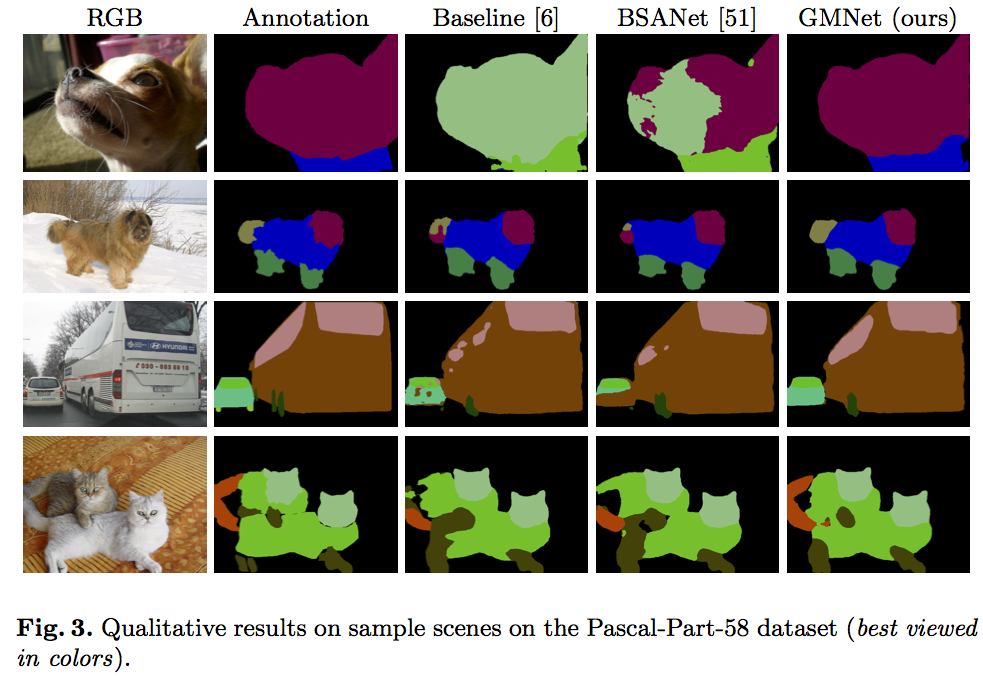
Contacts
For any information on the method you can contact
lttm@dei.unipd.it
References
[1] U. Michieli, E. Borsato, L. Rossi, P. Zanuttigh, "GMNet: Graph Matching Network for Large Scale Part Semantic Segmentation in the Wild", European Conference on Computer Vision (ECCV), 2020
xhtml/css website layout by Ben Goldman - http://realalibi.com