|
|
|
--
--
In coarse-to-fine learning previous knowledge, acquired on a different but related task, is transferred to a new situation. We tackled two coarse-to-fine refinements in semantic segmentation: respectively, at the spatial level and at the semantic level.
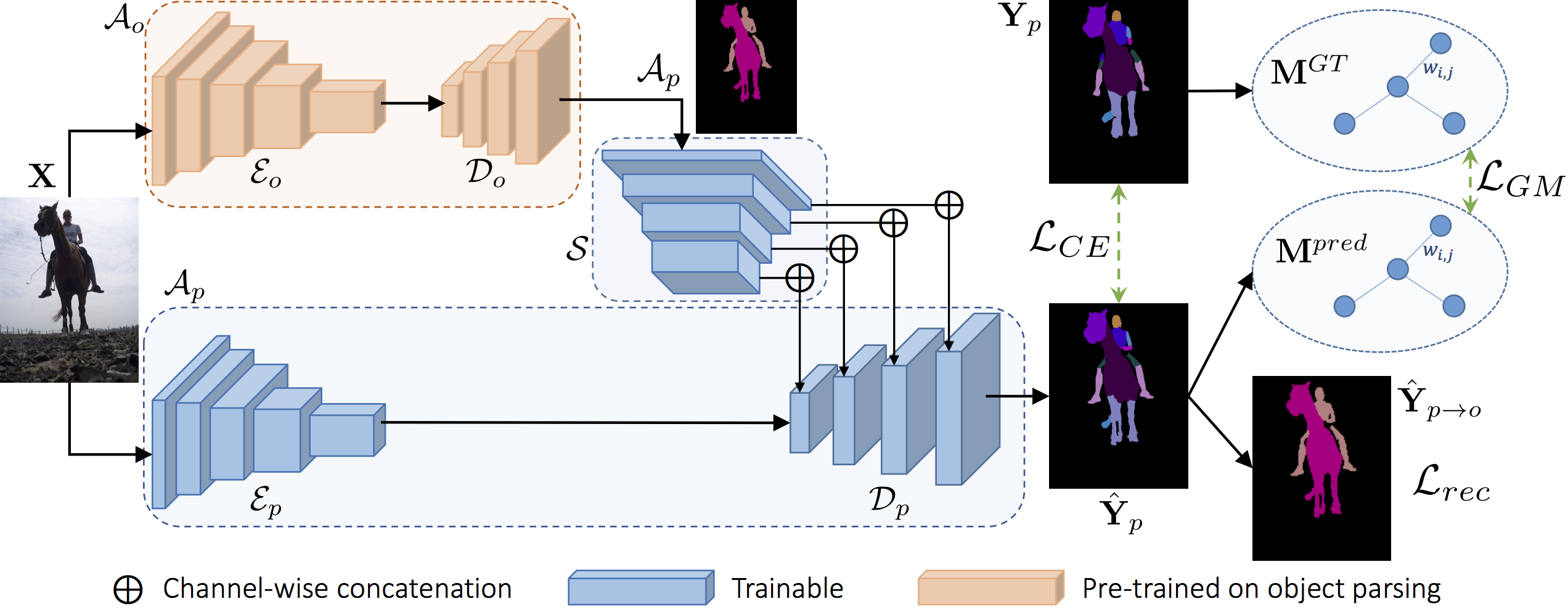
- The coarse-to-fine refinement at the spatial level is the decomposition of object-level classes into their respective parts. In [5], we investigated the multi-object and multi-part parsing in the wild, which simultaneously handles all semantic objects and parts within each object in the scene. Even strong recent baselines for semantic segmentation face additional challenges when dealing with this task. In particular, the simultaneous appearance of multiple objects and the inter-class ambiguity may cause inaccurate boundary localization and severe classification errors. For instance, animals often have homogeneous appearance due to furs on the whole body. Additionally, the appearance of some parts over multiple object classes may be very similar, such as cow legs and sheep legs. Current algorithms heavily suffer from these aspects. To address object-level ambiguity, we propose an object-level conditioning to serve as guidance for part parsing within the object. An auxiliary reconstruction module from parts to objects further penalize part-level predictions in regions occupied by an object which does not contain the predicted parts within it. At the same time, to tackle part-level ambiguity, we introduce a graph-matching module to preserve the relative spatial relationships between ground truth and predicted parts. Experimental results show that we were able to achieve state of the art results on this task outperforming concurrent approaches.
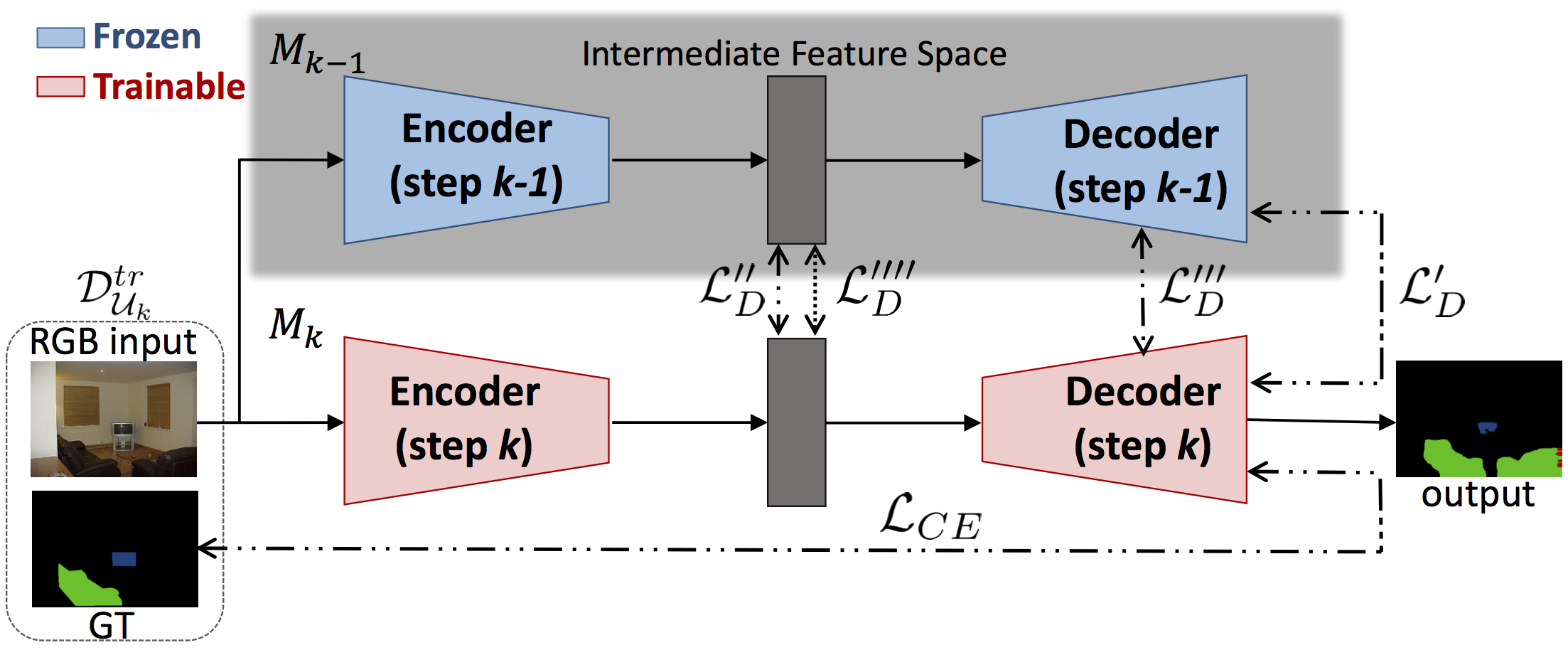
- In the coarse-to-fine refinement at the semantic level, previous knowledge acquired on a coarser task is exploited to perform a finer task. For instance, in [5] we addressed the multi-level semantic segmentation task where a deep neural network is first trained to recognize an initial, coarse, set of a few classes. Then, in an incremental-like approach, it is adapted to segment and label new objects categories hierarchically derived from subdividing the classes of the initial set. For example, a generic coarse class furniture was divided into finer classes such as desk, dresser or cabinet. We propose a set of strategies where the output of the coarse classifier is fed to the architectures performing the finer classification. Furthermore, we investigate the possibility to predict the different levels of semantic understanding together exploiting shared multi-task representation, which also helps to achieve higher accuracy.
Related Papers:
[5] U. Michieli, E. Borsato, L. Rossi and P. Zanuttigh,
GMNet: Graph Matching Network for Large Scale Part Semantic Segmentation in the Wild
, European Conference on Computer Vision (ECCV), 2020.
[5] M. Mel, U. Michieli and P. Zanuttigh,
Incremental and Multi-Task Learning Strategies for Coarse-To-Fine Semantic Segmentation
, MPDI Technologies, 2020.
|
|